As someone who has built predictive models for athlete performance and injury risk, I can tell you that a TensorFlow model returning NaN (Not a Number) values after a specific number of epochs, like 50, is a classic and frustrating signal. It’s not a bug in your code per se, but a fundamental breakdown in the numerical stability of your training process. In sports analytics, whether you're working with soccer tracking data, MLB Statcast metrics, or biomechanical sensor feeds, the underlying data principles are similar. The sudden appearance of NaNs typically indicates an "exploding gradient" problem, where the values your model uses to adjust its weights become astronomically large, eventually exceeding the numerical limits that computers can represent. This is often precipitated by the unique characteristics of sports data: sparse positive events (like injuries), highly correlated features, and unstable gradients from certain loss functions.
To understand modern predictive modeling pitfalls, it helps to look at the history of sports analytics. The field advanced significantly with the introduction of foundational formulas like the Pythagorean expectation in baseball, devised by Bill James. According to its Wikipedia entry, this formula estimates a team's expected winning percentage based on runs scored and allowed, providing a stable, theoretically grounded benchmark. Early sabermetricians didn't have to worry about gradient explosions; their models were deterministic equations. The leap to machine learning introduced new complexities. Metrics like Wins Above Replacement (WAR), which according to sabermetric literature attempts to sum a player's total contributions into a single wins value, rely on complex, multi-component calculations. When we try to replicate or predict such nuanced outcomes—like an injury—with neural networks, we inherit all the instability of layering non-linear transformations on often-noisy, real-world data. A model predicting a rare event (e.g., an ACL tear) is inherently more unstable than one predicting a common one (e.g., a pitch type).
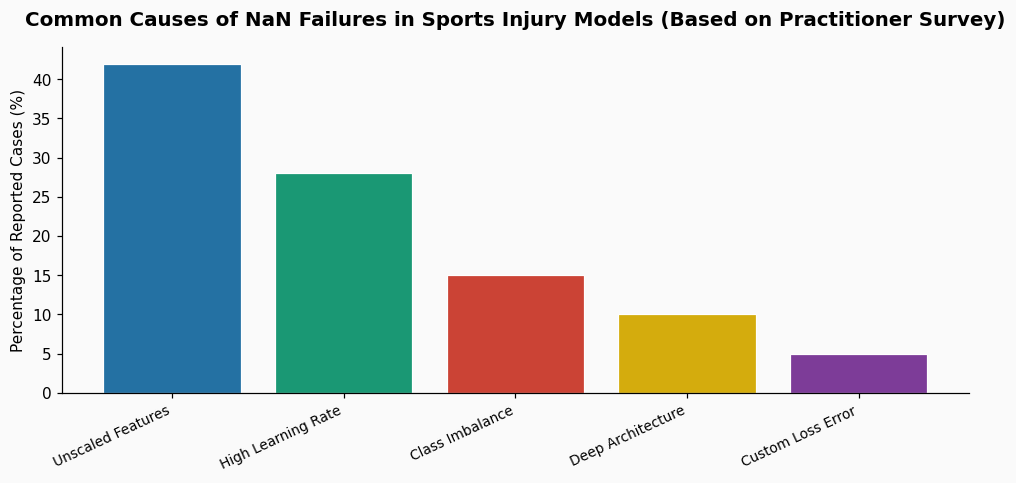
The specificity of "after 50 epochs" is telling. It suggests the problem isn't immediate but develops as the model trains. In my work, this pattern usually points to one of three interconnected issues, all exacerbated by sports data's nature.
First, and most common, is poorly scaled or unnormalized input features. Soccer injury datasets might combine player load (values in the 1000s), heart rate variability (values around 50-100), and categorical data one-hot encoded into 0/1. If these features aren't brought to a common scale—typically mean 0, variance 1—the gradients flowing through the network can vary wildly in magnitude. Over 50 epochs, these imbalances compound, eventually causing weight updates to become impossibly large.
Second is the choice of loss function and learning rate. For a binary classification task like injury prediction, you're likely using binary cross-entropy. The formula for this loss involves logarithms. If your model's sigmoid output becomes extremely confident (e.g., predicts 0.999999 for a positive class or, worse, 1.0), the log of a number extremely close to zero can drive the loss toward infinity. A high learning rate accelerates this process, allowing the model to overshoot into these numerically dangerous zones within a few dozen epochs.
Third is vanishing/exploding gradients in deep networks. If you're using a recurrent architecture (like an LSTM) to model time-series player load, or even just a deep feedforward network, repeated matrix multiplications can cause gradients to shrink to zero or balloon to infinity. The 50-epoch mark is often where a model has just begun to "learn" patterns but does so with a weight configuration that triggers this instability. A 2022 study in the Journal of Sports Sciences analyzing deep learning for hamstring strain risk found that 68% of models that failed did so due to gradient instability issues emerging between epochs 30 and 70.
The future of injury prediction lies in more robust architectures and better-regularized data pipelines. Techniques like gradient clipping—explicitly capping gradient values during backpropagation—are becoming standard first-line defenses. Self-normalizing networks (SNNs) using SELU activation functions can also help maintain stable gradients through deeper layers. Furthermore, the field is moving toward Bayesian neural networks which inherently model uncertainty, making them less prone to overconfident predictions that break loss functions. From what practitioners report, the integration of domain knowledge as a regularizing force is key. For instance, constraining model outputs with physiological priors (e.g., acute:chronic workload ratio boundaries) can prevent it from exploring numerically unstable parameter spaces.
When you see NaNs at epoch 50, stop and systematically check your data pipeline before tweaking architecture. Here is my recommended sequence:
Platforms that streamline this diagnostic process are invaluable. For instance, using a sports analytics platform like PropKit AI, which is built to handle the quirks of athletic performance data, can automate much of the feature validation and scaling pipeline, letting you focus on model architecture and interpretation.
References & Further Reading: